

The faster you receive data, the faster you can act... and the better your edge. From the early days of Wall Street to high-frequency trading plus other historical examples, we can learn from the past. Hundreds of millions have been spent on network infrastructure to achieve latency advantages.
On the blockchain, tackling latency requires understanding the critical role of infrastructure. In this webinar, Blocknative co-founder and CTO Chris Meisl explores the constant battle and emerging strategies for lower latency.
A full transcript is available below and the slides can be found here.
Recap Video
Transcript
Latency over different ecosystems
I thought I would start with a little bit of a story because Laurence gave you a little bit of my background, which started in working for NASA. What was latency when I was doing that work on deep space probes? Basically, at that time we had these probes that were out on Venus or Mars or farther out. And there's a certain amount of delay for the signal to get back to Earth and to be able to process. It might be a few minutes, it might be a few hours. So that's a pretty large amount of latency. But the actual latency that we experienced at the time was more like a day because you get the signal back, and then you have to interpret it. So there's this sort of computational element, human computational element, to figure out what to do next, in order to send signals to that spacecraft on any kind of adjustments, corrections, or whatnot.
That was my introduction to latency. And obviously, there's a pretty large latency there. Moving forward in my career I eventually got to the point where I was building ad tech solutions. And in ad tech, you're dealing with billions of events coming in a day, these are basically pageviews. And then you need to make decisions on those and then deliver a bid in order to capture that page view with the ad that you want to deliver. So you end up with complex bidding models, but they are all based on getting the data fast enough so that you have as much time as possible to make a decision within the window in which that auction is going to close. So now we're talking about latency that is measured on the order of hundreds or even 10s of milliseconds.
This brings us to today with blockchain - often people think “well, why do we really have to worry about latency? These blocks take a little while to make if you're on Ethereum. Post merge it's a 12 second cycle where we build these blocks so that doesn't seem like a lot of latency.” But, as we will see, latency matters.
Why is latency so important?

So why does latency matter so much? The reason is not technical. It is a very simple reason, which is… it's an information advantage to know about something sooner than someone else. And if there is money involved, then that means there's a trade advantage. And that trade advantage will then give the holder of that advantage more time, or get in front of other trades, in order to generate more money.

So latency very directly correlates to more money. That's why there's a lot of attention in this area. And there's a lot of effort in order to reduce latency, which leads to whenever you're talking about latency then you're talking about serious infrastructure. Because in order to provide these kinds of low latency solutions, you need a lot of infrastructure not just to make it resilient, but also to make sure that everything is as fast as possible.

Think of it like your pipes need to be as clean as possible so that everything can flow through as quickly as possible. So you have large infrastructure companies that do all sorts of custom deals with ISPs and other network infrastructure players to optimize the pathways to go faster than normal internet traffic. That’s why when we talk about latency, infrastructure matters - it matters hugely.

So, let's bring this home now to what's happening today. We're going to be focusing, obviously, on Ethereum. Let's talk about the transaction and, as a consequence, the MEV pipeline that we experience today.
As a quick review, the user has some kind of intent that they then sign through a wallet, and that wallet then sends that transaction through some service provider to a mempool, that mempool propagates around the world. Searchers then see those transactions in the mempool and do action on those transactions to make decisions and then send those reactions to the initial trade or the the initial transaction to a builder.
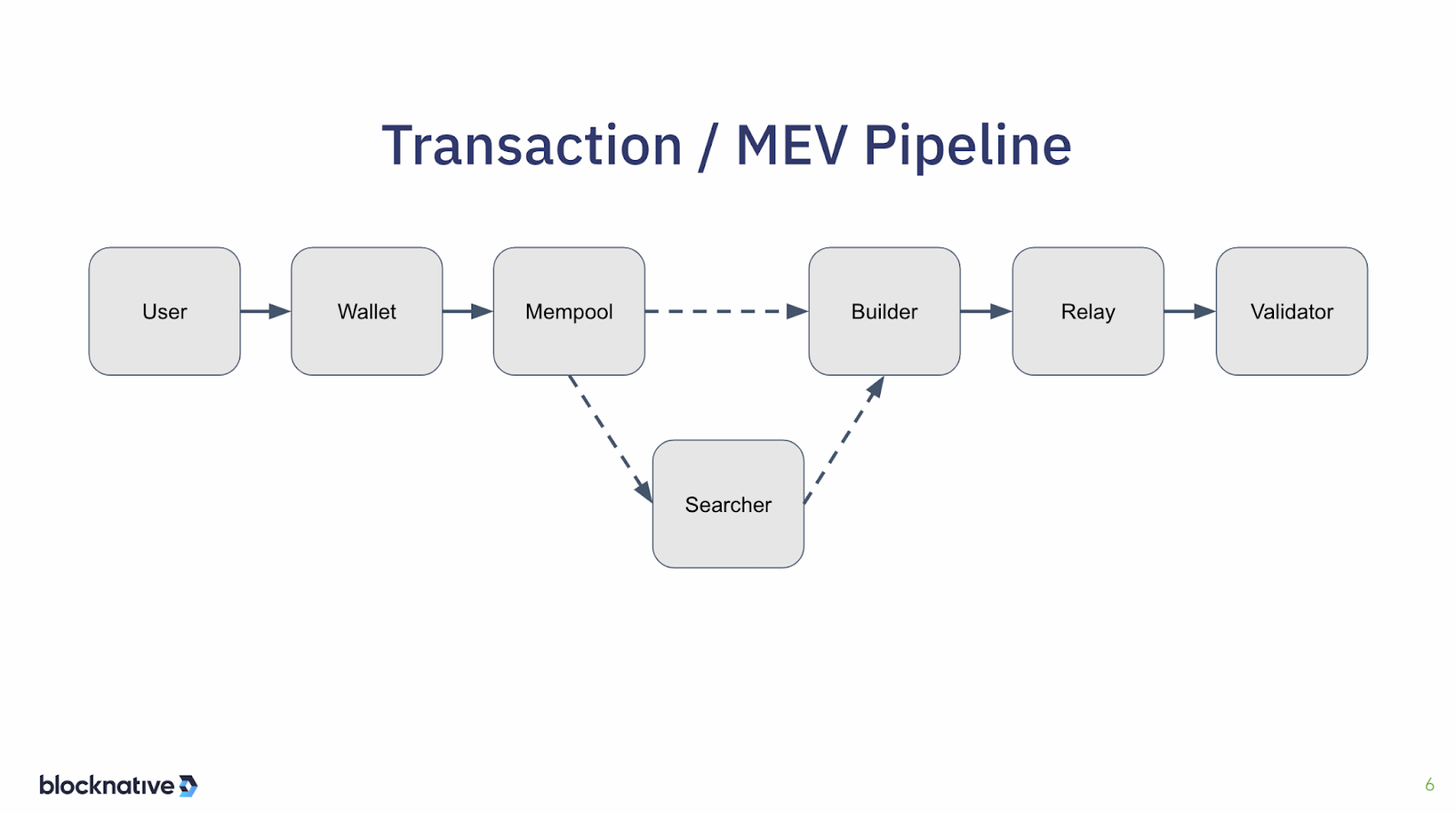
That would be, for example, a searcher sending a bundle to a block builder that may contain a front run or a back run or a sandwich. Then those block builders send the blocks that they build, with searcher bundles, to a relay. The relay makes the blocks available to validators via MEV-boost. When the validator is ready, somewhere in the slot to propose the next block, then that information contained within the block is available to them so they can do their proposal.
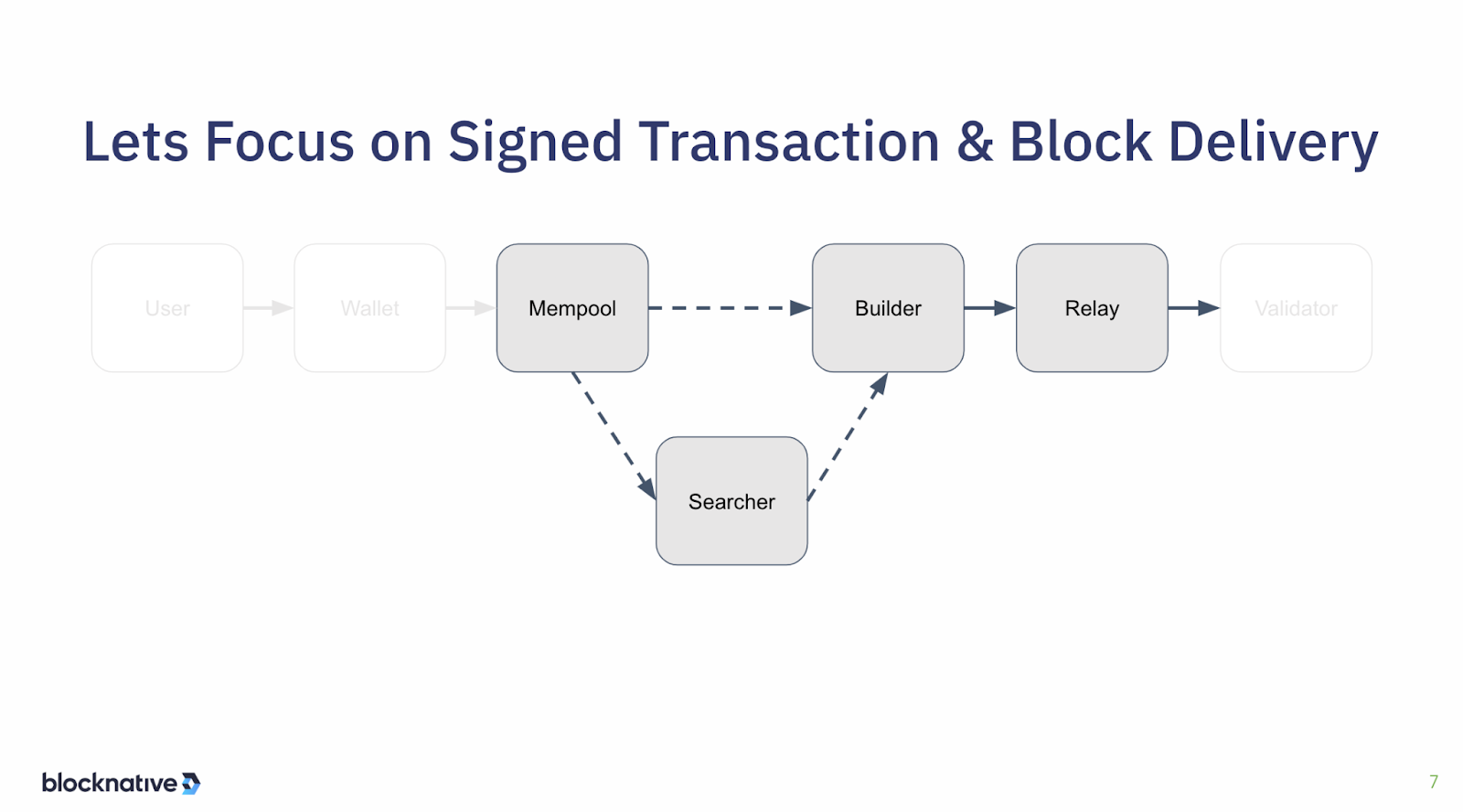
For our discussion, we're going to focus on the signed transaction part of this. That’s where the user intent has already been expressed - a wallet has signed the transaction and sent it to the mempool. We will not go earlier than that. We're also not going to focus on what the validator does, but more that we just get it to the validator. So this will go over a signed transaction receipt in the mempool all the way through block delivery to the validator. That is where we’re concerned about in this webinar on latency.
Types of latency—compute latency vs transport latency

I divide the latency that we are are going to be talking about into two main categories— there's compute latency and there's transport latency.
And to go back to the example that I gave from earlier in my career, the transport latency is sort of the light time from the spacecraft down to an earth receiving station, and then from the earth receiving station to wherever the computers are, and the people are, in my case, it was JPL, to actually process that information. And then the compute latency is going to be decoding and other kinds of computation on that, plus whatever kind of human computation is required in order to make a decision.
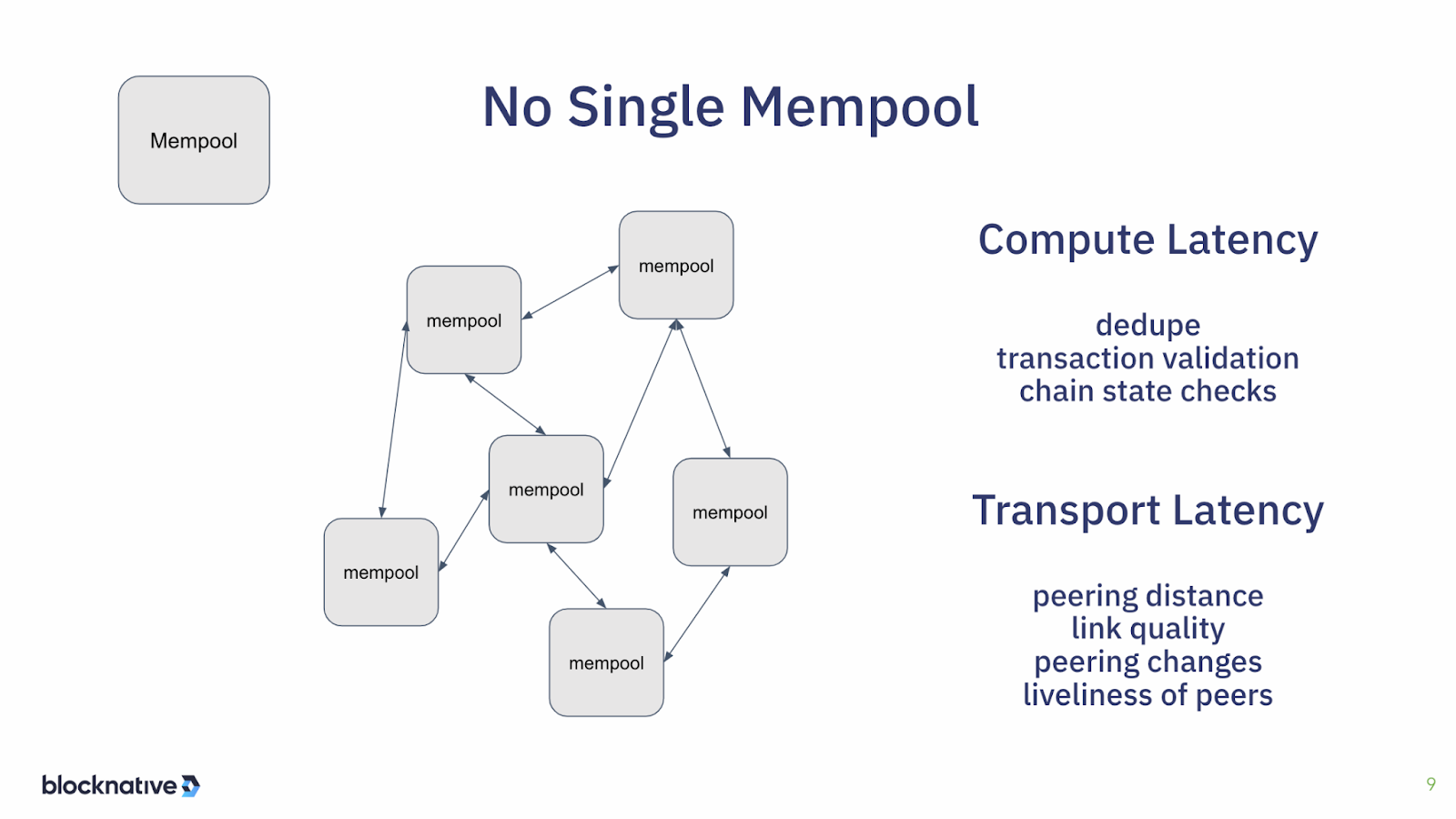
Now, I'm going to now work through those different elements of the flow of transactions and we'll talk about the latency inherent in each of those and how we can respond to them. So the first step is the mempool.
Quick reminder, there is no one mempool. Everybody has their own mempools, and there's a p2p network that tries to keep them synchronized, but this is, after all, a decentralized world. There is time it takes to go from one mempool to another and it's like a big mesh. And so there's a lot of delays there which are the kinds of latencies that we experience in the mempool. How close or far away are the peers to the current mempool that you're operating in? What is the quality of the network links? Do they stay up? Do they go down? Is a dial-up? Is it fiber? What is it?
Then these peers are changing all the time, so peers are up here, and then disappear, and the node that gets node or the nethermind node, or what have you, is constantly updating its peering table, and peers are leaving and peers are arriving. And there's a certain amount of time it takes to accept a new peer and verify that the link is good. And so that creates some latency which speaks to the liveliness of those peers. The less lively the peers are then the more churn there is within a particular mempool to be able to find more peers.
In order to get into the mempool, there is quite a lot of compute that has to happen. So there is a validation pipeline inside of a guest node or nethermind node, or whichever node you're using to verify that the transaction that has been received is, in fact, appropriate to put into the mempool. So you have to dedupe it— you have all these peers, a typical geth set up will have 50 peers. And so you might be getting the same transaction from each of them and you only want to take the first one.
Once you receive the transaction, you have to verify if it is formatted correctly and then validate whether it is an acceptable transaction. For example, you check that the from address has enough funds in it to properly fund the gas as expectated for that transaction. How do you actually do that? You have to look up the funds for that from address which might require a lookup in the database in the chain itself. And those lookups can be rather expensive.
If you're running geth, for example, the chain is stored in its fully mercalized format, which means that you're doing a lot of disk hops in order to find the data that you want which can be a little bit slow. And that speaks to finding the chain state in order to properly validate transactions that rely on that chain state which is all done from the from address. And depending on the complexity of that transaction, there may be other chain states that need to be fully qualified to make sure that they're okay.
Responding to latency challenges for the mempool

So how do we respond to all of these sorts of challenges for latency?
Well, one of them is, you do a lot of shortcuts on the validation. There are all kinds of tricks that you can do there to reduce the time it takes to do all of that validation. For example, maybe there is some sort of caching that you do to have some of the chain state in memory so that you don't have to go to disk. You can have larger sections of the entire chain mapped into memory so that you can get to it fast. There are all sorts of techniques used in order to get through that validation pipeline faster than then stock geth or a nethermind might do. And there's even some newer clients like Aragon, for example, that have a fundamentally different storage format under the hood. These lookups aren’t as inefficient and they don't need to do as many disk reads, making them faster for the validation.
Another way on the transport side is to use a private network to get access to pending transactions faster than you might just waiting over the peer-to-peer network and the BDN from Bloxroute. An example that's very popular among Hmong traders, and other infrastructure operators in the space.
Another option is optimizing the peering algorithm that's used in these node clients. A well-known one - there was actually a paper put out a few years ago - is a design called Perigee, which changed the peering algorithm so that it optimizes for low latency peers, as opposed to the stability of those peers, or the randomizing of the peers. Randomizing the peers is good if you want to have a really healthy network, but it's not so good for latency.
So Perigee focused on the latency issue, but it realized that in network topology, when you do a game where you optimize for latency, it's very easy to have network segmentation, which in the crypto world, we tend to call eclipses, as in the eclipse attacks—this is where a part of the network is isolated from the rest of the network. And so that was sort of abandoned as not such a good idea.
There was another product called Parry, a modification of geth in this case, which basically applies that for a few nodes, and that is advantageous to those nodes. But as long as that's not deployed very extensively in the network, then it doesn't cause some of the network problems, but it can give a few nodes a specific advantage. So those are some of the responses that teams have done in order to make mempools more efficient and current, especially if you're, let's say, a searcher.
Responding to latency challenges for searchers
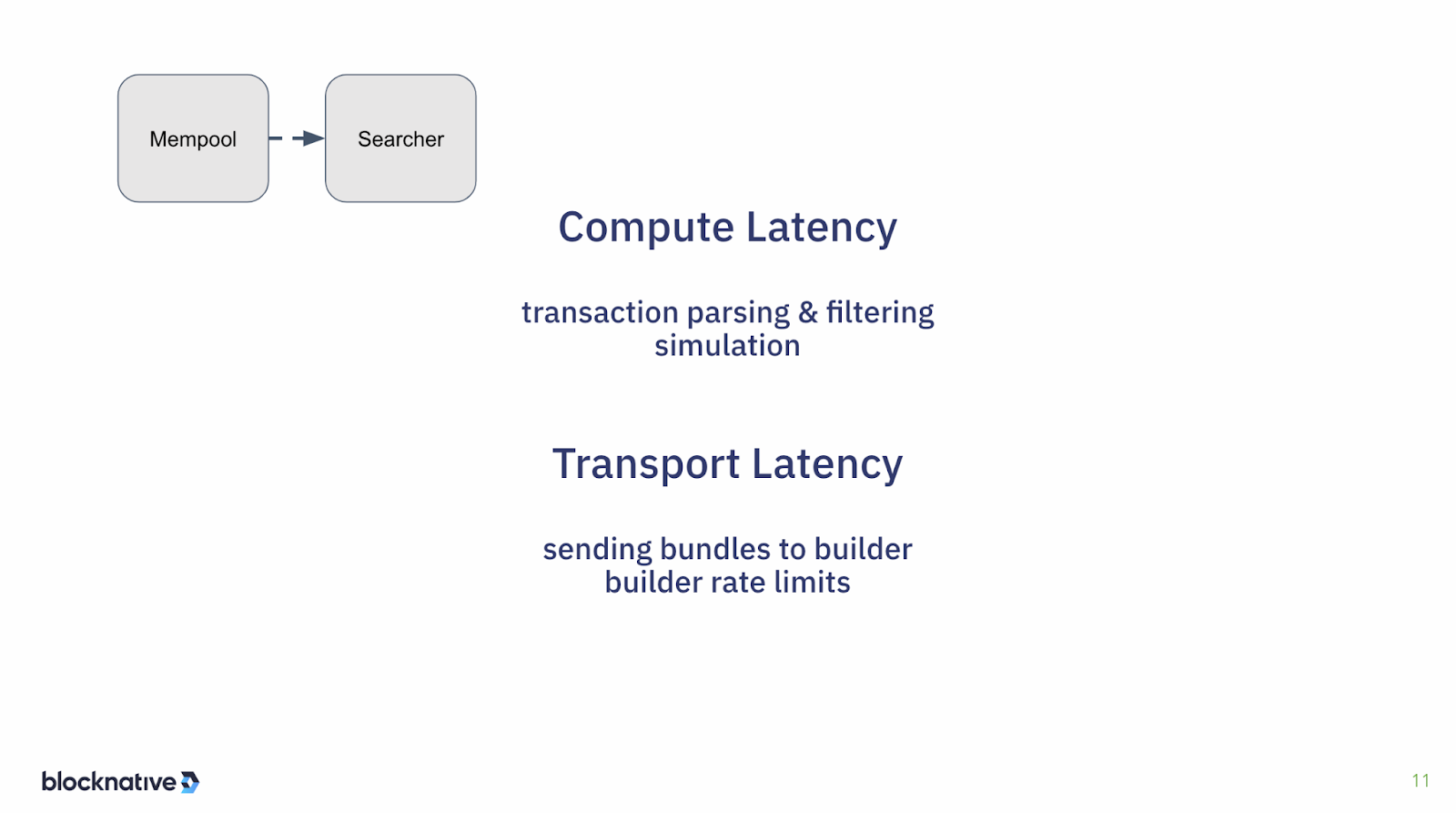
Speaking of searchers, we'll move on to that next one. Going from the mempool to the searcher, now you have more compute latency, because the searcher has to actually parse the transaction and then filter it to figure out if this is an opportunity to be able to capture some MEV.
Once the searcher has set up their capture, whether it's a front or back run or a sandwich, then you need to simulate that to make sure that the outcome is as expected and you're not going to send a bundle that is going to lose you money. And you might also want to simulate it under a condition where if the inputs aren't what you expect that it fails very rapidly, so you don't waste a bunch of gas.
And then the searcher also has, of course, the standard transport latency getting from the mempool to the searcher, and then sending those bundles on to the block builder and dealing with the rate limits that most builders will enforce. Builders will have rate limits in order to prevent too much spam from searchers or low-value bundles from a searcher because there's a compute cost to them since they're validating. Typically what builders do is create multiple tiers and there might be a fast tier and a slow tier. Depending upon your success rate - the quality of your bundles - then you get elevated to the fast tier versus the slow tier. That way a builder can manage their resources in order to get the best possible blocks without wasting too much time on low-value inputs.

So some of the responses that searchers have to this.
What we'll start with is proprietary compute environments, which is my euphemism for what is typically classified as alpha - this is searchers doing magical things under the hood that they're not going to tell anybody about in order to compute the bundles faster than other people. There are numerous techniques for that—we're not going to get into those.
The other opportunities are that a searcher can time their bundles against the slot periods, the blocks are typically prepared so that they can be proposed at the beginning of the slot or the end of the previous slot, depending on your point of view. Most validators are going to wait close to that edge in order to have the most valuable blocks. And a searcher is incentivized to be careful about their bundle timing because you want to put all of your compute, all of your capacity, into that partial period of the slot where you can provide the most value and have the most likelihood of being successful.
And then another one is to minimize the transport latency to the builder by co-locating with the builder. So let's say if the builder is operating out of an AWS region, then you know, determine where that region is, and then make sure that you're searching in the same region or even have a conversation with the builder and see if you can do a direct link. A direct connect link further reduces the latency connection by reducing the number of switches and routers you go through in order to get to that builder, which can be quite material.
Responding to latency challenges for block builders

So speaking of the builder now, moving through this pipeline, the builder of course, now has to validate every bundle coming in, has to make sure that it is in fact a valid bundle, that the value is in fact correct, and then it might have to do some filtering. Depending on which jurisdiction it's in it might have to do filtering based on jurisdictional requirements. For example, in the United States, we have a list of addresses that the government would prefer not to transmit. So if you're operating a builder that adheres to that then you would have to put in those filters and of course, that takes compute time which slows everything down.
And then you have to do calculations as a builder on prioritization of the bundles I talked about, like fast lanes and slow lanes. Then, once you've built the actual block, you need to simulate the block that you are in the process of building. You're simulating all of these combinations to make sure that the block that you finally produce is in fact a valid block.
And on the transport side the connection between the searcher and the builder is going to introduce some transport latency. And then you have to send it on to the relay, which has some transport latency there. And then the relay itself may have some limits: different relays have different limitations, some don't have a limit at all. Builders have to respect that, otherwise, you end up in the wrong tier because they will treat you potentially as spam. And you have to do that slightly carefully. You don't want to just rate limit your building - you want to actually do everything as fast as you can but always try to make sure that you handle that rate limit in a way where the best block always does get through. So there's a little bit of nuance there.

So the response to that, again, there's the proprietary compute improvements that you can do. So every builder has done all kinds of clever things to their build environment in order to be more efficient. It’s very similar to what the searcher does, but they're just doing it on a larger scale. Builders will typically be running much beefier hardware in order to have a fast compute capability. And they will also make sure that within their little ecosystem, if they're using external services, that they have very high-speed links. Builders also look at block timing, again, for the same reason I said before, which is that it's more productive to be building faster and better towards the end of or near the beginning of the next slot and you’ll get more success as a builder to have the highest possible bid. And of course, you would co-locate with the relay to reduce the connection time.
Responding to latency challenges for MEV relays

And that takes us to the relay. So this is pretty much the last one in the list here. The relay has to verify the signatures and verify the fee recipient. It also has to simulate the block to make sure that it's valid and that the bid is the actual value that would go to the validator and is an honest submission. And it might have the same or different filters, as I discussed before, based on any kind of regulatory constraints. And it has to do all of these things in order to make sure that the block that is delivered to the validator meets all of the conditions and is perfectly valid.
There have been some new innovations here in the relay space to do optimistic simulations. So in the case of bid validation, for example, or validating the block itself, then by doing an optimistic you can do that asynchronously so it doesn't slow down getting the block to the validator. To do that there is a bonding mechanism so that if the builder in fact did fail in creating a correct block then there's an economic mechanism to force the builder to make right with the validator since they delivered a bad block that the validator was either not able to put on-chain, or did put on-chain, but the promise via the bid was not achieved in the actual value that was generated. Several of the relays are moving in that direction.
And then the usual transport latency issues of getting the blocks from the builder and sending blocks to the validators. Sending the blocks to the validators on the transport side for relays is a little bit interesting because the relay is basically fanning out to the entire universe of validators. There are half a million validators around the world and they are all in different locations. So that's why relays have to have a lot of infrastructure to make sure that they can provide low latency to validators wherever they are in the world, whether they are in Asia, or whether they're in Europe or in the US, or in Africa or what have you. The latency needs to be low no matter what. And that requires configuring things in the right way in order to achieve that because validators do try to get to the edge to get the best possible block and there are some pretty strict constraints on how fast the relay has to respond to that.

So the responses are maybe not proprietary compute, but definitely a proprietary network with distributed edges where you have to do a lot of edge computing techniques in order to get close to the world validators are in. This means relays will have points of presence all over the world in order to have good coverage based on where the validators are.
Another way to approach this would be to just do full-on distributed relays. This would mean running multiple relays in different parts of the world to service those regions of the world and then have a proprietary network under the hood that tries to keep those synchronized as much as possible. Obviously, you'd want to co-locate with builders, or have builders co-locate with you and then potentially, you would co-locate with a validator pool.
So if there are certain validators, let's say Lido for example, that have a huge footprint. If you know where those validators are operating out of then you want to have the relay have a point of presence that's very, very close to that which is co-location. That would be advantageous to that validator pool because they're gonna get incrementally better blocks because they don't have to worry about the transport side as much.
So that gets us through the whole pipeline. I know that might seem a little bit exhausting but part of the message is that there are a lot of steps and a lot of places where there are all kinds of optimizations that can be done to improve latency and therefore to improve the value of those blocks and the value that is ultimately in our current setup which is captured by the actors that are involved: the validator getting the best possible block value, searchers getting the highest win rate on their blocks and things like that.
Latency Wars in TradFi

So I wanted to briefly switch to how this translates to traditional finance. This gives me a chance to put some color on this slide with Michael Lewis's book Flash Boys, which I highly recommend reading. It's a very entertaining view of how high-frequency trading works. The problems expressed in the book are basically the fundamental latency problems that I said at the very beginning: if you get some piece of information earlier than someone else does, and you can act on it, then that's going to translate into dollars.
And that's what a lot of these high-frequency traders basically did. And they realized that if they had super fast links, and if they could co-locate with the dozen or so traditional finance exchanges then they would have a big advantage in being able to arbitrage between a single trade distributing out to all of these exchanges, so that trade goes to exchange A and exchange B. And you have a faster link between A and B versus what a normal trading outfit can do.
So when you see that trade coming in and it happens on one exchange creating an imbalance between the exchanges it allows you to arbitrage that and HFT outfits we're setting up racks of high-speed computers in the basement of the exchanges or in the building adjacent to it. That became quite a good monetization technique for the exchanges themselves. So the exchange would set up and then basically buy the building next to it and rent out that space to HFT traders and say, “Hey, if you want to get ahead of things, you can and we'll give you some rackspace right here”. So it became its own little industry.
And then, of course, you can do fancy compute, like FPGAs to make it even faster than normal CPUs. And the response to that was—well there was a lot of responses to that, including some social pressure. So part of the main story of Flash Boys is the story of the iEX exchange, I think it stands for investor exchange, which traders can opt into a trick where the exchange knows the physical latency to every other exchange over the wire, and it would delay sending the trade to each exchange based on that latency and basically optimize for every other exchange to receive that trade at the exact same moment.
And, of course, they didn't allow any HFT traders on the premises when they received the trade. And that was very successful. It achieves the goal but less than 3% of all trades go through that platform. So it's not really that material. And of course, there have been regulatory changes. So in the United States, the US government has made some changes in order to have regulatory pressure on some of these techniques that are used by HFT. But they can’t really work if HFT can move much faster than Congress can adopt rules.

So, in the end, you can see that even in TradFi, infrastructure matters. It's all about the infrastructure, it's all about the pipes— it's about networking, high-speed compute and optimized compute.
How latency wars affect searcher, builder, and relay activity today

So, how does this affect the activity that searchers and builders and relays do today? What are the consequence of this? What is the natural direction that this might go in?

I think what we can expect to see, and we're already seeing some of this in a consolidation between searchers and builders, is that they are going to co-locate, or just skip that part and just become one. And so these are builders that are also doing searching. And there are huge advantages to that. They might accept other bundles from external searchers as well, but then they do their own searching on top of that and they can then do that with pretty much no latency at all because it's in the same compute environment as the block building that happens.
And then the other expectation would be that there will be a centralization of a builder conductivity to validators via relays or maybe even direct through proprietary networks. We're starting to see that now - more builders want to be on high-speed networks. Even the validators, especially pools, can be in a high-speed network, and the relay can be on a high-speed network, and everybody's sort of working together. And the number of high-speed networks is much smaller than the number of builders and validators, so there's centralization there.
Is MEV dystopia unavoidable?

So where does this lead? Does this, in fact, lead to MEV dystopia, which was described by the Flashbots team almost a year ago in Amsterdam. How do we avoid this sort of complete vertical integration, where you have a large validator pool that basically runs its own set of builders and its own set of searching, and, insofar as they can be successful at that, then they have an APY/ revenue generating advantage on their stake, and they could then plow that advantage back into their stake, increasing their validator pool set and creating a sort of a flywheel effect.
The next thing you have is this sort of dystopia where the entire network is no longer decentralized anymore. It's completely centralized at that point. So, is this inevitable?

I would argue that it is not.
And the reason why it’s not is that searching is an incredibly dynamic activity. New protocols are appearing all the time— new opportunities and new techniques. Builders can differentiate on all kinds of different block space offerings, it's not just MEV. There are other things that are going to become more and more valuable, especially as we layer on L2s and other compute concepts on top of the core Ethereum platform like Eigen layer. Then there's the value that the builder has in how they optimized the use of that block space.
There's going to be a lot of innovation there that I think is going to allow new entrants and smaller actors that can move very quickly to be able to be quite competitive. On the relay side— which, keep in mind that relays are a sort of a temporary thing until we have in protocol PBS— it is very possible that different validator pools are going to have different validator preferences, and that's going to create the need for multiple relays to service that we see that today. As far as you know, some of the relays do not filter any transactions, and some relays ensure some kind of sort of compliance with particular regulatory requirements in certain jurisdictions. And there's a demand for both of those.
So that brings us to today. And one thing that I wanted to add is that a lot of these ideas were proven or became front of mind over the last over. Last week there was an interesting event where a validator was able to extract a very large amount of funds by basically sandwiching a group of searchers. And they did that because they had visibility into the block, even though the block was not being propagated. And they could then swap that block out, because they were the official proposer at the time, and they could swap that block out with a block of their own making.
And because they had visibility into the block and searcher bundles, and they had to carefully construct a bait for those searchers in order to get them to max out their attempt to get profit or max their leverage. They were then able to pull all of that away from the searchers and capture it for themselves. And that was actually enabled by a vulnerability in relays that was very rapidly addressed.
This illustrates that there is an opportunity there for latency-based games, where if a validator wanted to do a switcheroo on the block after they had signed it, and they happen to be able to propagate that faster on the network, then the relay might have an advantage.
And so there's a lot of talk now in the relay community about how to mitigate that, because it's an interesting race condition of vulnerability to how the network operates. That is an example of exactly what we've been talking about in this presentation. And it's very real-world.
Continue the conversation

That concludes our presentation. I'm happy to continue this conversation with anyone on our Discord. Here’s a link for that, if anybody wants to check it out. Otherwise, it's been a pleasure speaking to you today. Thank you very much.




